Part 1 – What Does Flipping Others’ Content Really Do for You? From Thousands to Millions of URL Opens: Deciphering the Impact on Your Experience


I had been helping to promote a food blog when I noticed other food bloggers with magazines outside of food. I decided to add technology because I have always enjoyed building computers and have some coding experience. Then I decided to add health because food and health are closely related do to the fact our diet has a lot to do with our health. Now, just want to remind you I was here to promote a food blog. I was posting many recipes each day with very little results; however, I realized the magazines I was just flipping other people’s articles in were growing rapidly. I began to believe this was going to help me and I decided to try a 30-day experiment. On 3/27/24 I took a screenshot of my numbers at the beginning; I took another on 4/16/24 and a final one 30-days later on 4/26/24. As you can see, I was able to go from 2000 plus URL opens to over 1 million in those 30 days. Now let’s see what that did for me and my reason I am here.

As you can see a few days later I made myself a certificate of achievement. So, I had figured that my original poor results were because of my lack of flipping other’s materials. Well, my technology magazine had taken off and Flipboard showed it off in one of their weekly storyboards however, not a great place for food recipes. My new health magazine made more sense so I would give it a try. Tecnology was doing well, and health was a broader subject, so it was doing even better. I wanted to add more magazines so I had one that you could flip anything into and passed everything very quickly. So, to recap I was here for food and on 3/27/24 I was over 2000 URL opens and 30 days later I was over 1 million URL opens. So, what did this do? Well, take a look back at the black arrows in the first square and last square, now look to the left and see that I made myself a certificate of achievement. Unfortunately, it didn’t help my food magazine one bit, however, look at my magazine follows in technology. Why didn’t it help? Could I take advantage of technology with all these followers? I have found some answers to these questions in part 2.
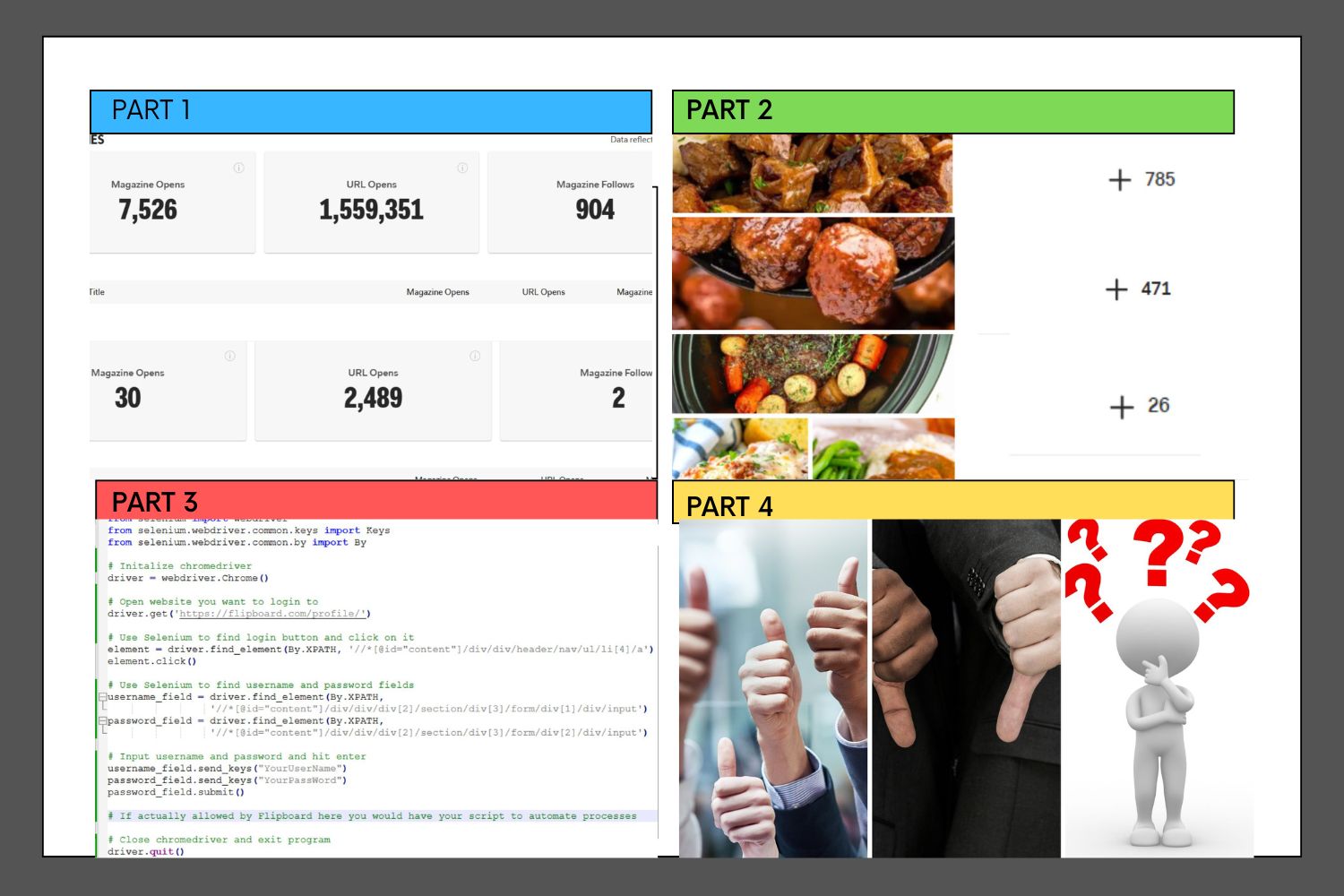
Part 2 – Recipe Matchup: Ever Wonder How a Bowl of Lettuce Got 400 Flips? Users’ Picks vs Flipboard Interns’ Favorites

So, I want to point out that my experience is based on the food industry on Flipboard, and I realize each industry may be different on Flipboard, I hope there are some things that may relate to other users in different industries. Although disappointed after realizing my magazine, the one that mattered, did not improve, I must admit some positive results that did. Although not where I primarily do food blogging posts, I have begun seeing more results from outside sources due to my increased participation in flipping and gaining followers. Due to my desire to understand how things work, which I am nowhere close to yet, and doing this, I have learned that there are certain days and times that my post is going to have a better chance of success than others. Unfortunately for me, titles make a huge difference, I am not one with words. This brings me to another point. I fail a lot when I try to use ChatGPT (AII) and the person I am trying to help with the food blog often tells me they didn’t understand the title. So, if you choose to use something like ChatGPT make sure you learn about prompting. Every once in a while, I get a good idea and I can feel the confidence in the title and usually have success. There are times I feel the stars have aligned, success is all but guaranteed and it just doesn’t work out and I believe that can happen and all you can do is keep reflipping it every once in a while and maximize what you can out of it. Hopefully you are not like me and are quick tempered and thin-skinned; luckily, I can let go quickly and move on. but it sucks when you think something good fails.
My question in Part 2 was, “ever wonder how a bowl of lettuce gets 400 flips?”. I am sure everyone has seen an article and wondered how it got so many flips. The interesting thing is that a news article can be read and decided if you liked it or not in real time. Obviously, with food, you do not have time to make it and taste it to decide if it is any good. I have told you that I learned that there are better days and times for me. Also, titling makes a big difference, along with originality. Unfortunately, I also believe I could have Wolfgang Puck write a tasting menu and post it under my magazine, and I will still get blown away by someone with a can of tomato sauce with a couple spices in it or potato chip dip. If you look back at the Part 2 featured image and look at the number difference between the top and the bottom, it is huge. Do you have to be an intern for Flipboard, featured on Microsoft Edge home feed, and have Flipboard change the algorithm for you? The answer appears to be YES… The other option is to have a team of about 5 and each have three websites and post about 30 to 50 recipes every two hours, then switch recipes with each other and change the title and featured image. Good luck competing with that. You see, people who are professionals at their cuisine get nothing, while these people just take up all the space, drown others out, and get all the clicks. I have some screen shots to show examples of what I am talking about. They will be updated to Part 2 late tonight, 5/9/24.

Sorry for so much blocking, trying to hide other’s identities. So, this is an example of being on the Microsoft Edge home feed at the same time as Flipboard. The results, as you may assume, are pretty good. I just want to point out that I work on 3 different operating systems and 5 different browsers, and I still believe Microsoft Edge with the Bing search engine is the worst. However, for me, it is good for ideas, and I do see a lot of material on there that is on Flipboard. Unfortunately, i hear they are not taking new food bloggers currently.

This image shows how the post on the top left has the “NOW” status, and a couple hours later it still has the “NOW: status. On the right-side corner, both top and bottom, you can see the different times.

Ever see a post with the status “NOW” and it has over 100 flips? Well, now you will most likely know why. So here is an example like the last one, however, you can tell the real status by clicking on the ‘+’ symbol, and it will show you how long it has really been out there.

And there it is, the bowl of lettuce. I could make the best dish hands down and I still can’t beat a bowl of lettuce. “Are You Flipping Crazy?”
In part 3, that will be out in a couple days, I promise it is not all about technology or coding. I take a look at why something so simple is not provided by Flipboard or why they would not allow us to code the automation. Is this just something else to prevent the playing field from being level?
Part 3 – Have 75 Magazines to Flip an Article to and Tired of the Wash, Rinse, and Repeat? Exploring Web Automation, Web Scraping, and Selenium vs BeautifulSoup

Once again, I do not want to assume everything works the same for each industry. I am not fortunate enough to place a single article in a magazine and have it flourish. I have to put it in every magazine I possibly can. This was my biggest frustration when I joined Flipboard. So, for me, when I want to post an article to a magazine, I have to click on create a flip, insert link, write something interesting up top, then select a magazine and click add. So obviously, in my mind, I thought it was crazy to have to repeat that process for every magazine you wanted to post to. Why not do it once and then pop up a box with all your magazines and check all the ones you want to post to?
Let’s face it, this is a feature Flipboard could easily implement. I can’t pretend to know the answer why they don’t. So, like most people without answers, I’m left with conspiracy theories. It could be as simple as Flipboard feeling it needs user involvement for their concept to work or as dubious as creating an unlevel playing field.
Everyone is familiar with Captchas; A website attempt to make sure you are human. This probably makes most people think of bots as something nefarious. Yes, like most things created for good, they can be used for evil. We are simply looking at web automation to do simple tedious tasks for us. For example, flipping your post to multiple magazines. I am going to assume that Parade Magazine isn’t manually flipping their material. I would assume they use RSS. This is the method I would assume Flipboard would hopefully eventually implement. RSS feeds are a powerful tool for automating the distribution and consumption of web content, enabling users and systems to stay updated with minimal manual intervention. So, for now, without that as an option, we can look at automating the process ourselves or paying someone to do it. In order for us to be able to do this, we must be able to extract data from the website. The first method we would want to use is via an API Key. By using an API when available, you leverage a more robust, efficient, and legally compliant method to access the data you need. Unfortunately, I do not believe Flipboard is providing its users with an API Key. This is where web scraping comes in and how Selenium and BeautfulSoup can achieve this. Selenium is an open-source automation testing tool that supports multiple programming languages. It allows you to simulate user interactions with a web page, such as clicking buttons, filling out forms, and navigating through pages. On the other hand, BeautifulSoup is a Python library used for parsing HTML and XML documents. It creates a parse tree that makes it easy to extract data from HTML Combining Selenium and BeautifulSoup allows you to leverage the strengths of both tools, making it possible to scrape complex and dynamic websites efficiently.

I apologize, this code is a hot mess. The purpose of this program can be found in the sub routine parse recipe. With a given URL I want the title, description and image. I use Selenium to load the page and extract the HTML and parse the extracted HTML with BeautifulSoup to get the title, description and image URL. The rest of the program is me inputting a text file with websites I use and then writing to a text file with the title and description and saving the downloaded images to a folder. The reason for the overuse of error checking is the fact that sometimes images are replaced with a social media copy. This is an issue you wouldn’t have with an API Key. Also, keep in mind if the structure of a web page changes, most likely your code will need to change. This is why API is more stable. There are places to get free API Keys with limited usage. Microlink API and NewsAPI for example.
Part 4 – The Takeaway: My Experience and a Critical Examination of the Good and the Bad, with the Ultimate Question: Do We Stand a Chance Against the Flipboard Algorithm?





